我们已经在前面介绍过双变量描述性分析,知道这是关于两个变量间关系或联系的描述,也是关于这个关系强度的测量。那么如何测量这种关联度?这是接下来要说的。
我们先来看关联度测量(measures of association)这个术语。类似于集中趋势(平均数、众数和中位数)和离散分布(measures of dispersion)的测量(极差、标准差),关联度测量也是一种总结性的统计数字:它会告诉我们两个变量间的关联程度有多强。当然,它也能显示出两个变量间是否存在关联性。但局限在于,它不能告诉我们到底是哪个变量在影响着哪个变量。两个变量可能会“共变”(co-vary),也就是X和Y同时变化,如广告投入和产品销售量同增同减。但是,当X和Y不存在任何关系时,它们也有可能在表面上呈现出有关联的样子。例如,销售量和广告投入可能不存在任何关系,你之所以观察到二者相关(同增同减),原因是竞争者的活跃程度在发生变化。这就涉及外生变量(extraneous variable)或混杂变量(confounding variable)的问题,我们会在稍后予以讨论。
最基本地,关联度分析会告诉你两个变量间到底是正相关、负相关还是根本不存在任何关系。正相关是指如果一个变量值增加,那么另一个变量值也会增加。例如,广告投入增加,销售量也增加。负相关是指一个变量值增加时,另一个变量值则会减少,例如,消费者的年龄越大,升级手机的可能性越低。
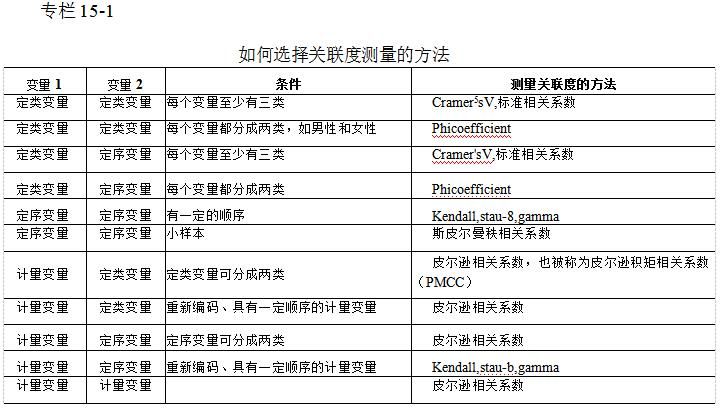
正如集中趋势和变动测量一样,关联度的测量也有好几种方法,究竟用哪种方法很大程度上取决于分析的是何种类型的变量。专栏15-1列出了不同类型的变量适应的关联测量方法,其中最常用的是卡方相关系数(Chi-Square contingency coefficient)和皮尔逊相关系数(Pearson'sr)。
扫码关注调研家公众号,随时随地获取调研家观点


关注公众号
调研家将为您提供
一对一专业服务,根据您的项目情况,为您定制专属解决方案
Copyright © 2023 SurveyPlus 瀚一数据科技(深圳)有限公司 粤ICP备18114013号
![]() 粤公网安备44030502004015号
粤公网安备44030502004015号






























