原创作者:胡婧炜
说起实验,大家眼前首先浮现出来的场景可能是穿着大褂的科学家,堆满试管仪器的实验室,还有小白鼠等。我们经常也能听到一些实验,比如耳熟能详的伽利略的“两个铁球同时着地”的实验,改革开放或者扶贫政策实施前的试点工作,还有最近关于新型冠状病毒肺炎的各种新药和疫苗的实验等。
实验看似远在天边,其实近在眼前。我们每个普通人经常会有意无意地进行各种实验。比如说,爱美的女士们,在镜前试验哪个色号的口红让自己看起来气色更好;望子成龙的家长们,反复考证哪一个培训课程可以让孩子的成绩突飞猛进;还有肺炎期间宅在家中自学成才的各位“厨师”们,一定也反复调整过配方来让一道菜或一次烘焙更加成功。
为什么要做实验?
我们为什么要做实验?尽管实验的操作者既有天才也不乏凡人,实验的设计有精准的也有与蹩脚的,一次实验可能产生重大的发现也可能导致错误的推断,然而每一个实验背后的目的却直观明了:我们试图通过这种手段,去发现纷繁复杂的现象背后,什么是真正的原因,什么是其导致的后果。发现因果关系是科学研究的重要使命。Mill阐述过因果关系成立的三个条件:
(1) 原因发生在结果之前;(2) 原因与结果相关联;(3) 除了该原因之外,没有其他更合理的解释。
实验与因果关系这一逻辑不谋而合:首先,人们在实验中先控制原因,然后观测结果;其次,人们在实验中可以看到原因的变化是否导致结果的变化;最后,在实验中,人们可以通过不同的方法来排除其他一些不合理的解释。因此,实验是自然科学与社会科学中研究因果关系的一种广泛使用的方法。
随机分组:随机实验设计成功的关键
经典的随机实验要求将被试随机分派到不同实验组或者控制组。举例来说,我们想通过实验来发现某一个网络英语课程是否能改善学生的英语成绩。在这个实验中,干预条件是学生上这一门网络课程。通过比对上过这门课的学生和没上过这门课的学生的英语成绩,我们来推断这个课程是否有提升英语成绩的功效。
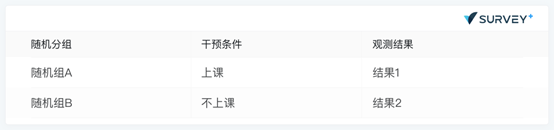
在这个随机实验中,非常关键的一个因素就是参与实验的被试被随机分派到实验组(随机组A)和控制组(随机组B)。也就是说,一个被试被分派到组A还是组B是完全由几率决定的,而不是受其他因素影响的,就像我们扔一个硬币,正面被分派到组A,反面分派到组B。
为什么随机实验中随机分组这么重要?随机分组能够确保组与组之间无论是在可观测到特征上还是在不可观测到的特征上都是等同的,它们之间唯一的差异是干预条件的不同,这样如果我们最终观测到了结果上的差异,
我们才能够说这一差异是由实验条件决定的,而非其他条件决定的。
在上面的例子中,如果分组不是随机的,比如我们让被试自愿选择是上这个课还是不上这个课,然后我们发现上完课的组在英语成绩上明显好于没有上课的组,我们一定能将其归功于这一网络英语课程吗?试想一下,自愿选择上课的组可能原本英语成绩就好于自愿选择不上课的组,他们对英语的兴趣更浓,因而向来英语成绩就好,也更有兴趣选择上一这门网课。另一方面,即便二者一开始在英语成绩上旗鼓相当,自愿选择上课的被试想改善英语成绩的动机可能更加强烈,他们上不上这门课,成绩的改善都会好过不上这门课的被试;而那些自愿选择不上课的被试,他们即使上了课,最终成绩可能还是比不过那些自愿选择上课的被试。也就是说,在没有随机分组的情况下,上完课的组的英语成绩好于没有上课的组的英语成绩,可能和这个课并没有什么关系,而是由其他因素决定的。
社会调查和市场调查中用到实验的场景很多,比如通过实验比较不同的测量工具的测量效果,通过实验比较不同的文字、图片、视频材料对受访者行为与态度的影响等。在调查还没有计算机化的时代,随机分组由工作人员通过随机数等方式来确定,这一过程很容易受到人为的影响(比如,访员为了回避难以执行的实验条件而随意改变分组),从而影响到实验的结果。计算机在随机分组上有独到的优势。下面我们通过两个例子来讲解如何做实验。
实验题设计一:正向量表 VS 负向量表
有些研究者认为量表的方向会影响受访者的答案——受访者更倾向于选择量表的起始端,而不管量表实际的方向是什么。简单来说,如果量表是正向的,受访者更倾向于表达正向的观点;而如果量表是负向的,受访者则更倾向于表达负向的观点。
要检验量表的方向是否会影响受访者所填报的答案,我们可以这样来实施这个实验。假设我们提问受访者这样一个问题:
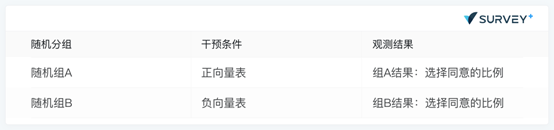
您是否同意如下观点:在家办公可以提高工作的效率。
针对这一问题,我们使用的干预条件是量表的方向。其中正向的量表是:非常同意1—2—3—4—5 非常不同意。负向的量表是:非常不同意1—2—3—4—5 非常同意。
根据上文的论述,我们需要将受访者随机指派给正向的量表(随机组A)和负向的量表(随机组B),如下图所示:
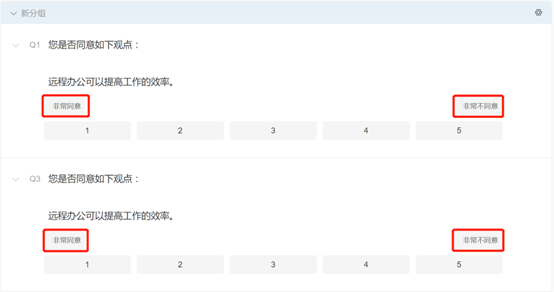
我们在调研家问卷设计平台这样操作这个实验:第一步,在问卷编辑界面录入这两道问题。可以看到,这两道题唯一的区别是量表的方向,即量表两端的标签不同。
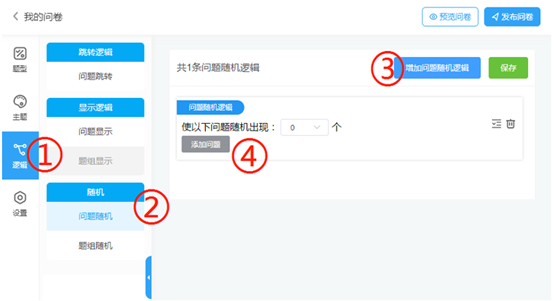
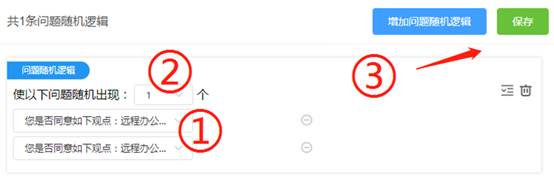
第二步:点击左侧面板中的“逻辑”(①),进入逻辑设置页面,在“随机”一栏,选择“问题随机”(②),点击右上方的“增加问题随机逻辑”(③),出现了问题随机设置页面,点击“添加问题”(④):
第三步:在上一步点击“添加问题”后,选中我们刚刚录入的两道问题(①),并将随机出现问题的数量设置为1(②),即表示每位受访者将随机指派给这两道问题中的一道。然后点击右上方保存(③),这个随机实验就设置好了。
在数据收集完成后,我们可以观察组A选择非常同意的比例是否显著高于组B,并据此作出量表的方向是可以影响受访者答案的推断。
在之前的文章中,我们提到了上下文效应(回顾《浅谈数据收集的各种效应(Effect)》)。沿用上一期的题目,受访者将被随机分派到以下A、B两组的一组。
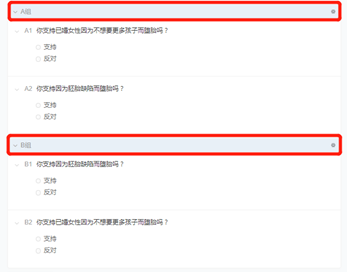
A组:
B组:
我们想要检验在没有受到“因胚胎缺陷而堕胎”一题影响的情况下(即A组,受访者先回答“因不想要孩子而堕胎”一题,不会受到“因胚胎缺陷而堕胎”一题的影响)和受到“因胚胎缺陷而堕胎”一题影响的情况下(即B组,受访者后回答“不想要孩子而堕胎”一题,会受到“因胚胎缺陷而堕胎”一题的影响),受访者支持“因不想要孩子而堕胎”的比例是否有显著的不同。

与上一个例子不同,这里每一个实验组都需要回答两道问题。如果沿用上一个例子的方法,尽管我们可以设置为4道题随机出现2道,但并不能控制出现哪两道。而实际的需求是,A1必须和A2绑定在一起出现,B1必须和B2绑定在一起出现。在这种情况下,我们需要用到题组随机。
同样,第一步:在问卷编辑界面录入问题。注意,此时我们需要将两组问题录制在两个题组中:
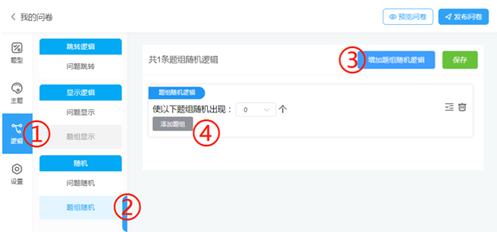
第二步:点击左侧面板中的“逻辑”(①),进入逻辑设置页面,在“随机”一栏,选择“题组随机”(②),点击右上方的“增加题组随机逻辑”(③),出现了题组随机设置页面,点击“添加题组”(④):
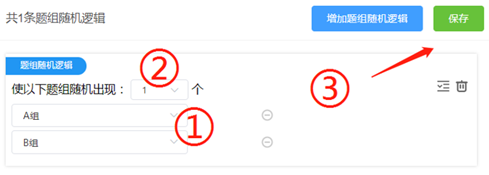
第三步:在上一步点击“添加题组”后,选中我们刚刚录入的两个题组(①),并将随机出现题组的数量设置为1(②),即表示每位受访者将随机指派给这两组问题中的一组。然后点击右上方保存(③),随机实验设置完成。
注:此题也可以用随机顺序的方式实现,受篇幅限制,此处不赘述。
在数据收集完成后,我们观察组A支持“因不想要孩子而堕胎”的比例与组B支持“因不想要孩子而堕胎”的比例,并据此作出上下文效应是否存在的推断。
扫码关注调研家公众号,随时随地获取调研家观点


关注公众号
调研家将为您提供
一对一专业服务,根据您的项目情况,为您定制专属解决方案
Copyright © 2023 SurveyPlus 瀚一数据科技(深圳)有限公司 粤ICP备18114013号
![]() 粤公网安备44030502004015号
粤公网安备44030502004015号































